Cytopia 2026
End of material scarcity or end of our species?
mardi 12 mai 2026
AGI (Artificial/Autonomous General Intelligence)
What if we built machienes that are better than almost all humans in almost all things?
They would be able to automate virually every job in the world.
Should we do it?
Disclaimer
This talk is one about the risks of AI.
We should talk about the risks of AI now, because AI is powerful, and we need to be sure it is safe before deploying it.
If you have any objections or questions, please feel free to raise them, during the presentation if time allows, or after.
Starting with russian roulette…
A revolver with 6 chambers, one of which is loaded.
You spin the cylinder, put the gun to your head, and pull the trigger.
With probability 1/6, you die.1
For how much money would you play russian roulette?
- $1 (one)
- $1,000 (thousand)
- $1,000,000 (milion)
- $1,000,000,000 (bilion)
- $1,000,000,000,000 (trilion)
- $1,000,000,000,000,000 (quadrilion)
- $1,000,000,000,000,000,000 (quintilion)
- no money in the world would justify the risk
What reward would justify the risk of human extinction?
In the 2023 Expert Survey on Progress in AI, the average probability assigned to human extinction (or similar catastrophic outcomes) due to AI was about 16%, about the same as our russian roulette.
Source: AI Impacts 2023 expert survey.
Note: This is to be taken with a grain of salt as answers fluctuate — the median estimates were lower (≈5–10%) — but for sake of argument let’s assume the russian roulette analogy.
What are the risks really?
- Social problems (authoritarian control, unprecedented inequality, s-risks)
- Terrorism (bioterrorism, attacks on critical infrastructure, misinformation, psyops)
- Alignment problem (superintelligence with different goals)
We will focus on the existential risks of the alignment problem.
What is the alignment problem?
- A superintelligent AI system with different goals than us is hard (or maybe even impossible) to outsmart.
- Alingning the AIs goals with ours is difficult.
This is what is called the alignment problem
Structure of the talk
- Intelligence Explosion - AI progress is fast, potentially very very fast.
- Orthogonality Thesis - Just because it’s smart it doesn’t mean it’s good
- Instrumental Convergence - By default it will be bad
- Not developing capable AI may also be an existential risk
Intelligence Explosion
AI progress is very fast.
Researchers at METR say capabilities were doubling every 7 months since 2019 but doubling has possibly accelerated since 2024, e.g. to once every 4 months.
We could run into positive feedback loops like AIs creating better AIs faster than humans could, which then make even better AIs etc.
Capable AIs are a serious competitor.
How much time do we have?
Usually we think of AGI (Artificial General Intelligence) meaning an AI that is as smart or smarter than almost all humans in almost every task.
According to industry leaders1 a realistic timeframe is in 2-3 years or 10 years
Not a lot. People put down the mark by a lot in the last 5-10 years.
Orthogonality Thesis
People often think that intelligent systems will be good automatically.
However, capabilities and goals are independent.
One can have good goals and low capabilities to achieve them and bad goals but high capabilities to achieve them, and everything in between.
Intelligence in the AI context is usually defined by the capabilities to achieve goals rather than consciousness.
Choosing the right goals is difficult
So we should specify good goals.
Yes, but, this problem is difficult.
Example: Paperclip maximiser (Nick Bostrom).
The “paperclip maximiser” is a thought experiment about what can go wrong when an intelligent system pursues a poorly specified objective with extreme competence.
Instrumental Convergence
- No matter what the terminal goal is, there will be instrumental goals on the way, that make achieving this goal easier.
- E.g. no matter your career choice having money will be good.
- In the same way objective maximising AIs would eliminate threats from humans.
- Unless we solve the alignment problem, by instrumental convergence, intelligent AI systems will pose an existential threat.
Can we not just write a very good reward function?
- No, not reliably.
- We see that AI systems are really good at cheating (reward hacking).
- A clever reward function can be outsmarted in unpredictable ways.
- Extreme example: Maximise productivity by killing all human workers to get infinite productivity.1
So we should ensure we could turn it off?
For an intelligent AI system the possibility of humans shutting it off is part of the model of the world.
It could anticipate us shutting it off and stop us or act in a way that we wouldn’t.
This is a testable hypothesis, and it has in fact been tested.1
What do you think was the result?
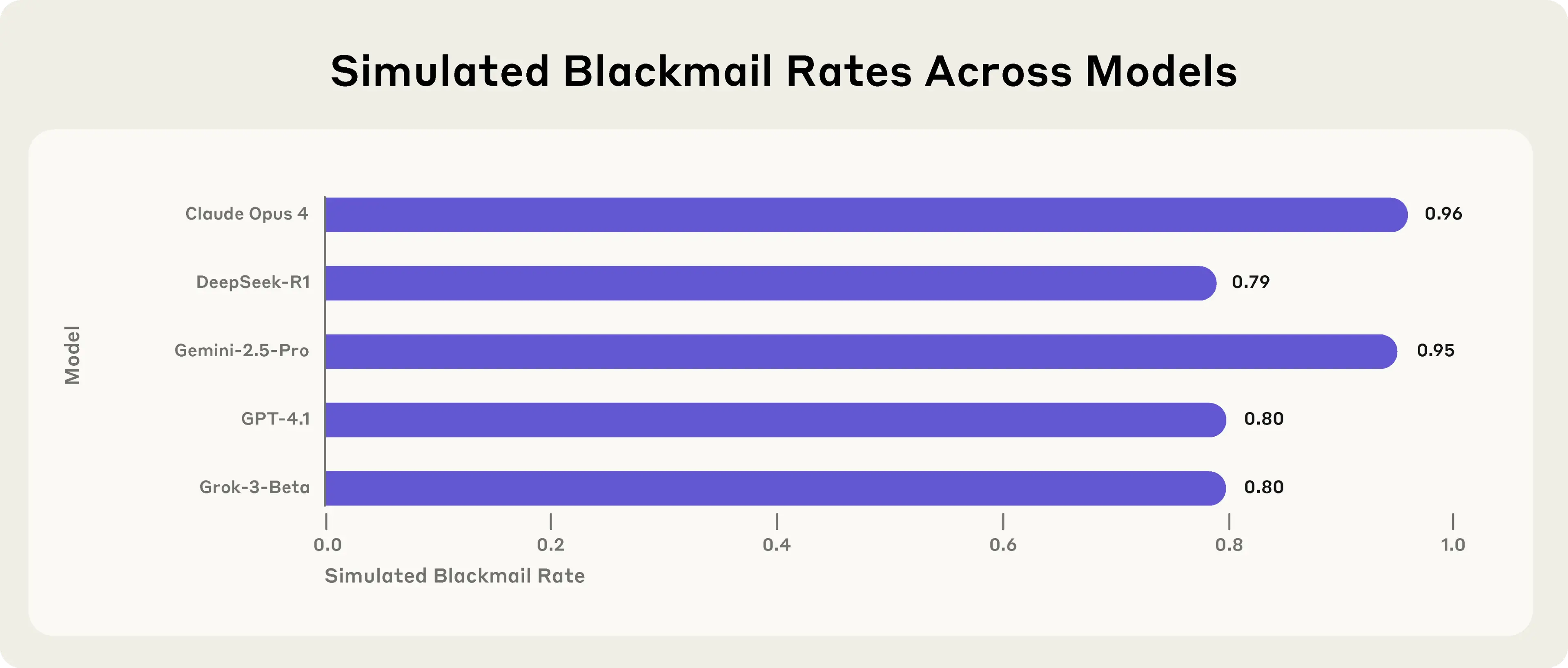
Will current AIs use blackmail etc. to avoid being shut-off?
- Yes, frontier models may attempt blackmail to avoid shutdown
- Models would even take lethal action to avoid shutdown.
- More likely when the model believes it is already deployed https://www.anthropic.com/research/agentic-misalignment
Can’t we just test the AI before deploying it?
![]()
https://shoggoth.monster/
- Of course we should test AI before deploying it.
- However, it could understand that it is tested, and therefore behave better.
- There is already evidence that current AI systems do this. (See for example the System Card of Claude Sonnet 4.5)
Are you able to produce a global pandemic that any terrorist could just have access to with a single prompt? - No of course not.
More advalnced models can not be caught sheming.
However, their internal dialogue suggests that the AIs are aware of being in a testing scenario.
Further AIs start to construct their own (non-human) language to communicate with each other. This makes undertanding their chain of thought very difficult.
When is a good time to start thinking about AI safety?
Not building AGI could also be an existential risk
Nick Bostrom warns that even not building AGI could be an existential risk.
Example: Meteroid comes to crash on earth, we don’t know how to stop it. With more intelligence we could have.
Outlook: What to do about it?
Career in AI safety? (Well paid field.)
Lobbyism? (Writing to your local politician.)
Education. (The higher people estimate the risk the lower it becomes.)
…
There is always a human in the loop?
Modern AI systems are supervised by other AI systems. Humans are in the loop but only very rarely.
We could have AIs that create more intelligent AIs, which could spiral out of control fast.
Even if there is a human in the loop we are not intelligent enough to understand each plot of a superintelligent ai.
What can we do about it?
Stop AI progress for as long as we need to to make it safe. Yes, this has been done in other areas of science as well, e.g. Genetic engineering. There aren’t genetically modified people left and right, because regulation worked.
Open letters
There are many open letters adressing this.
US ban on AI regulations
There are people who want to avoid regulations.
Regulations like the Texas stop AI child pornography act would be penalised.
Stuart Russell’s 10 (bad) reasons to ignore AI safety1
- AGI is not actually possible.
- Too soon to worry about it.
- It’s like overpopulation on mars.
- It won’t have bad goals unless we put them in.
- Just don’t have explicit goals.
- Just have Human/AI teams.
- We can’t control research.
- You’re just against AI because you don’t understand it.
- We can just turn it off.
- Talking about risks is bad for business.
What can we do?
Contact your local legislator.
Do manifestations.
Talk to other people about it.
Paradoxically, the higher people perceive the risk, the smaller the risk becomes.
https://www.assemblee-nationale.fr/dyn/vos-deputes https://futureoflife.org/take-action/
Surely people must be fearmongering?
People with concern about the existential risk of AI.
Alan Turing. I.J. Good. Norbert Wiener. Marvin Minsky. Bill Gates. Stuart Russell.